Redes neuronales aprendizaje Supervisado y no supervisado
Recordemos un poco de lo que se hablo en las clases presenciales sobre las redes neuronales, recuerda que dijimos: Las redes neuronales artificiales están basadas en el funcionamiento de las redes de neuronas biológicas. Las neuronas que todos tenemos en nuestro cerebro están compuestas de dendritas, el soma y el axón: Las dendritas se encargan de captar los impulsos nerviosos que emiten otras neuronas. Estos impulsos, se procesan en el soma y se transmiten a través del axón que emite un impulso nervioso hacia las neuronas contiguas.
Para hacer mas sencillo el concepto, diríamos que una red neuronal no es más que una formula matemática que nos permite resolver un problema.
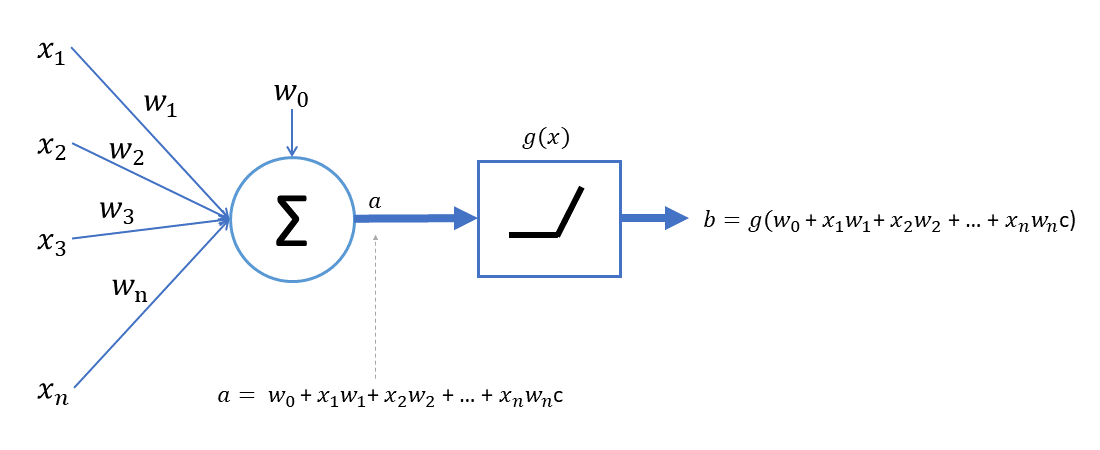
A esto se le llama perceptron simple ☝
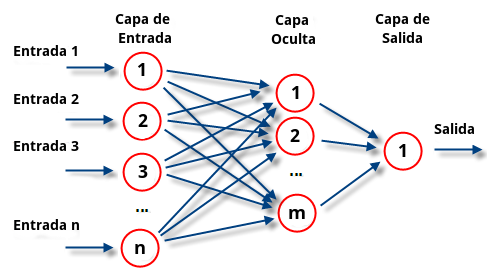
También los hay perceptrones multicapa es decir cuentan con más funciones o formulas que combinadas nos permiten obtener el resultado deseado.
Aquí un ejemplo de un perceptron multicapa👆
Una red neuronal o perceptron también llamado esta dividido de la siguiente forma, observa la imagen a continuación.
Bueno ahora veamos unos ejemplos que vimos en clase del uso de un perceptron simple y despues un perceptron multicapa.
De forma gráfica tenemos un perceptron que tiene los siguientes datos:
Los datos de entrada serian 3,4 y -2, tiene cada uno de ellos un peso que serian .2,.6 y .01 también llamados ponderación(cual dato tiene más valor o peso respecto a los otros), contamos con una sumatoria y una función de activación.
Para resolver este problema haríamos lo siguiente:
- Una vez tenemos estos datos y pesos, se deben multiplicar los los datos por sus pesos, y sumar los resultados.
2. el siguiente paso seria llamar a la función de activación.
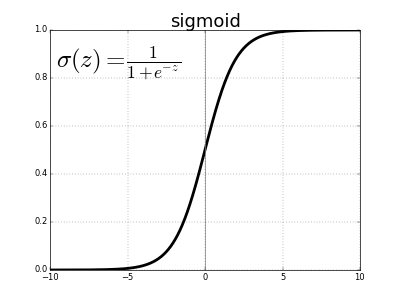
Se han propuesto muchas funciones de activación, pero por ahora describiremos solamente una. Históricamente, la función sigmoide es la función de activación más antigua y popular. Se define como:
Listo tenemos finalizado el ejercicio.
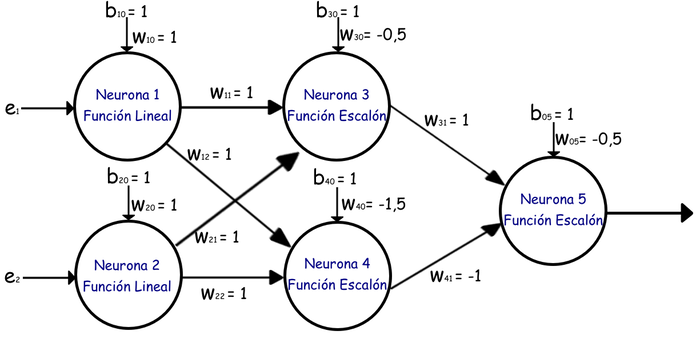
Ahora veamos un perceptron multicapa...
Observemos este ejercicio☝ vean que tenemos los mismos componentes (datos y pesos) y uno extra el de color
violeta llamado umbral sus valores son de 1. Para resolver esta red haríamos lo siguiente:
1. Colocarnos en el primer nodo de la red y ver cuales son sus entradas de datos y pesos
estamos en ese nodo de color azul de arriba👇
si nos paramos sobre el vemos que esta recibiendo dos entradas
el 3 y el 1 como pesos y el 1 y 2 como datos, y un umbral de 1
hacemos el calculo
El resultado es 6, esto mismo haríamos con el otro nodo de abajo, el cual recibe 2 y 4 como pesos, 2 y 1 como datos. hacemos la operación v= (2)*(1) + (2)*(4) + 1=11, recuerda que el 1 del final es el umbral.
Ahora que ya tenemos los resultados llamamos a la función de activación que para este caso utilizaremos la siguiente: la función lineal f(x)=x
Al pasar los dos resultados obtenidos tendríamos: f(6)=6 y f(11)=11 y tenemos la primer capa resuelta, pero aun falta la segunda capa en la cual haríamos el mismo proceso.
Hagamos:
En los nodos azules obtuvimos 6 y 11, 6 para el de arriba 11 para el de abajo. Nos colocamos en el nodo naranja de arriba y vemos qué datos y pesos están entrando así como el umbral.
estamos colocados aqui 👇
y observamos que este nodo recibe 6 y 11 los resultados de los primeros nodos o capas y como pesos recibe 3 y 2, hacemos los cálculos v= (6)*(3) + (11)*(2) + 1=41 y para el segundo nodo el de abajo seria v= (11)*(1) + (6)*(5) + 1=42 estos resultados obtenidos los enviamos a la función de activación y tendríamos f(41)=41y f(42)=42, hemos terminado.
Tarea resuelve los siguiente problemas.
Bueno esto lo hemos recordado pues es necesario conocer como funcionan las redes neuronales, el día miércoles estaré subiendo la segunda parte de la clase donde hablaremos más a fondo de una de las redes neuronales no supervisadas y supervisadas. Para pasar lista deja un comentario con tu nombre en la parte de abajo.👇 También si tienes dudas de como se resolvieron los problemas planteados, deja un comentario para que lo resolvamos.